大家好,昨天進行了資料的處理,將無法直接輸入模型的資料做型態轉換,然後以one-hot coding和數值兩種方式表示寶可夢屬性,再去除不需要的資料,以及以0和1表示寶可夢勝負。今天要做的是將寶可夢對戰資料分成訓練資料、驗證資料、測試資料,再來將寶可夢資料標準化。
先匯入Numpy,分割資料集的方法跟上一個題目一樣,用亂數分組成訓練資料、驗證資料、測試資料,各組資料比例為6:2:2:
import numpy as np
data_num = combats_df.shape[0]
indexes = np.random.permutation(data_num)
train_indexes = indexes[:int(data_num *0.6)]
val_indexes = indexes[int(data_num *0.6):int(data_num *0.8)]
test_indexes = indexes[int(data_num *0.8):]
train_data = combats_df.loc[train_indexes]
val_data = combats_df.loc[val_indexes]
test_data = combats_df.loc[test_indexes]
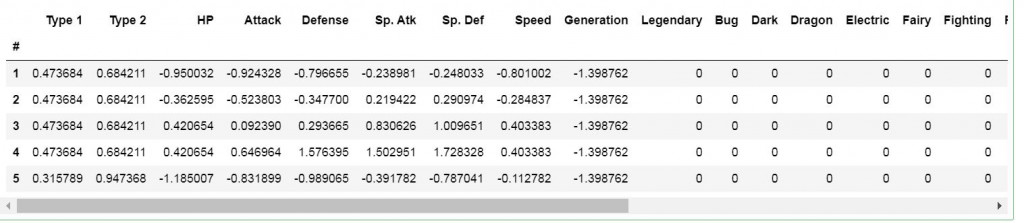
再來就是將資料標準化,其中數值表示的屬性與其他數值資料的標準化方式不同,而用one-hot encoding的資料就不用標準化。
數值表示的屬性標準化的方式是將資料除以19(總共19種屬性),將數值縮放至0與1之間:
pokemon_df['Type 1'] = pokemon_df['Type 1'] / 19
pokemon_df['Type 2'] = pokemon_df['Type 2'] / 19
再來其他數值資料(生命值到進化階段資料)的標準化方式是跟上一個題目一樣,是使用標準分數(Standard Score),讓資料聚集在0的附近:
mean = pokemon_df.loc[:, 'HP':'Generation'].mean()
std = pokemon_df.loc[:, 'HP':'Generation'].std()
pokemon_df.loc[:,'HP':'Generation']=(pokemon_df.loc[:,'HP':'Generation']-mean)/std
pokemon_df.head()